| | Grid-enabled Weka: A Toolkit for Machine Learning on the Grid by Rinat Khoussainov, Xin Zuo and Nicholas Kushmerick
In the end of the day, Grids are about Grid-enabled applications. While a number of general-purpose libraries for scientific computing have been adapted for Grids, many more opportunities remain in various specialist areas. We describe here an ongoing work on Grid-enabled Weka, a widely used toolkit for machine learning and data mining. Weka is a widely used toolkit for machine learning and data mining originally developed at the University of Waikato in New Zealand. It is a large collection of state-of-the-art machine learning algorithms written in Java. Weka contains tools for classification, regression, clustering, association rules, visualisation, and data pre-processing. Weka is open source software under the GNU GPL. It is easily extensible, which allows researchers to contribute new learning algorithms to Weka, keeping it up-to-date with the latest developments in the field. As a result, Weka has become very popular with academic and industrial researchers, and is also widely used for teaching purposes. The main focus of Weka is on classifier algorithms. Simply put, a classifier maps a set of data instances onto a finite set of classes. Each data instance is described by its attribute values. For example, predicting whether it is going to rain based on observations of sky, air temperature, humidity, and wind can be viewed as a classification task. Each data instance includes values of the observation attributes, eg (sunny, warm, humid, strong), and the available classes are {rain, dry}. The goal of classifier learning (or training) process is to derive a classifier from a set of labelled data (ie a set of data instances together with their correct labels). The idea is that a classifier learned on a labelled data set can then be used to predict class labels for future (unlabelled) data instances. Learning a classifier and using it to label data can be time consuming and require significant amounts of memory, especially for large data sets. Unfortunately, parallelising and distributing classifier learning is a difficult research problem on its own. Nonetheless, there are a number of simpler functions and usage scenarios in Weka that can still benefit from distributing the work on a Grid. The most obvious are labelling, testing, and cross-validation functions Labelling involves applying a previously learned classifier to an unlabelled data set to predict instance labels. Testing takes a labelled data set, temporarily removes class labels, applies the classifier, and then analyses the quality of the classification algorithm by comparing the actual and the predicted labels. Finally, for n-fold cross-validation a labelled data set is partitioned into n folds, and n training and testing iterations are performed. On each iteration, one fold is used as a test set, and the rest of the data is used as a training set. A classifier is learned on the training set and then validated on the test data.  | | Grid-enabled Weka, usage scenarios. | In Grid-enabled Weka, which is being developed in University College Dublin, execution of these tasks can be distributed across several computers in an ad-hoc Grid. The labelling function is distributed by partitioning the data set, labelling several partitions in parallel on different available machines, and merging the results into a single labelled data set. The testing function is distributed in a similar way, with test statistics being computed in parallel on several machines for different subsets of the test data. Distributing cross-validation is also straightforward: individual iterations for different folds are executed on different machines. The quality of a classifier often depends on various algorithm parameters. The same classifier may need to be trained with different parameters to obtain better results. In our system, the user can run a training task on a remote machine. This allows the same user to train several classifiers in parallel by launching multiple Weka tasks from the user's computer. The two main components of our system are Weka server and Weka client. The server is based on the original Weka. Each machine participating in a Weka Grid runs the server component. The Weka client is responsible for accepting a learning task and input data from a user and distributing the work on the Grid. The client implements the necessary functionality for load balancing and fault monitoring/recovery. It also allows the user to specify resource constraints for a given task and takes these into account when allocating the jobs to servers. The server translates client requests into calls to the corresponding Weka functions. It also provides additional functions like data set recovery from local storage after a crash. The same server can be used by several different clients, which allows users to share resources of the same machine. The system uses a custom interface for communication between clients and servers utilising native Java object serialisation for data exchange. The obvious next step is to convert it to an OGSA-style service using, for example, a Globus API toolkit. An important advantage of the current implementation is that in a trusted and centrally controlled environment (eg a local computer lab) it allows for utilising idling computing resources with minimal set up, configuration, and maintenance efforts. This is especially convenient for machine learning practitioners who may not be proficient in parallel computing or Grid technologies. The Grid-enabled Weka is currently replacing the original Weka in Elie, a machine learning-based application for information extraction developed in University College Dublin. Links:
Grid Weka: http://smi.ucd.ie/~rinat/weka/
Weka: http://www.cs.waikato.ac.nz/~ml/weka/
Please contact:
Rinat Khoussainov, Nicholas Kushmerick, University College Dublin, Ireland
E-mail: rinat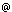 ucd.ie, nickucd.ie ucd.ie, nickucd.ie |


