Rapid Prototyping for Embedded Parallelism
by David Johnston, Martin Fleury and Andy Downton
While an embedded system has a more specialised role to play than a PC or workstation, the diversity of embedded applications is no less wide and their requirements are no less demanding. The RaPPID project (Rapid Parallel Prototyping in the Image/Multimedia Domain is developing a methodology to rapidly prototype high-bandwidth, compute-intensive embedded applications which are amenable to parallelisation. Example application areas are radar and image processing.
The approach is based on software components, whereby the software overhead of handling parallelism; of interfacing to proprietary parallel hardware; and of performance monitoring and tuning are abstracted into application-oriented (cf. system-oriented) 'classes'. Parallelisation has traditionally been a dead-end route for application software, as parallel hardware becomes redundant and particular parallel languages became less favoured or unsupported.
Instead the aim of the RaPPID project is to support the parallel execution of applications, that are expressed in a traditional sequential form, such as C++. The choice of the RaPPID classes selected and the (composable) manner in which they are used, gives clues to a 'harness' (the underlying software framework) as to the parallelism that may be exploited.
The resulting application code can run on any conventional serial machine, or on any parallel machine for which a suitable harness has been written, because the form is uncommitted to any type of parallel architecture. The harness dynamically monitors performance and optimises execution parameters such as granularity.
A variety of harnesses have been developed in CML (Concurrent Meta-Language) as the power of a functional language (code or 'functions' can be manipulated with the facility of data) provides an efficient mechanism for system prototyping. The very simplest case of data decomposition provides an illustration. If a user writes a software module to match the following CML type signature, then the user's software can be executed in parallel:
signature DATA_PARALLEL =
sig
type input;
type output;
val process : input -> output;
val combine : output * output -> output;
val split : input -> input * input;
end;
Here, the harness manages the parallel execution of the task, splitting the input recursively until the required granularity is achieved or until further splitting would become meaningless. Note, the user's code is purely sequential, and is in C++ rather than CML. Similar separations of concerns are possible for both geometric and pipeline parallelism.
Compare the protocol stack of a traditional parallel execution harness with that proposed by the RaPPID project (the left and right of Figure 1 respectively). The objective is to move towards a more uncommitted form of parallelism in order to provide unified support for a wider range of parallel and indeed hybrid parallel architectures with such components as Digital Signal Processors (DSPs), conventional Central Processing Units (CPUs) and Field Programmable Gate Arrays (FPGAs).
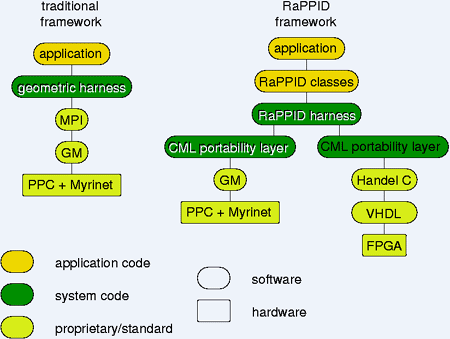 |
| Protocol Stacks. |
The traditional protocol stack model was used to port a geometrically parallel Augmented Reality (AR) application to a message-passing architecture. The real-time performance and parallel efficiency of 90% achieved constitute a baseline system for future comparison. The hardware consists of four PowerPC (PPC) processors connected by a high speed Myrinet network.
The harness was written on top of the MPI (Message Passing Interconnect) standard which in turn uses the Myrinet proprietary GM (Glenn's Messages) communication library.
In contrast, the portability layer of the RaPPID harness being developed supports the small and elegant CML model which is based on CSP (Communicating Sequential Processes). Adopting a clean CSP model allows the harness to be supported on a variety of architectures, and Figure 1 shows how this may unify the programming of FPGAs and message-passing architectures. A suitable mechanism for bringing FPGAs into the fold is Handel C. This is a concurrent C-based and CSP inspired programming language which compiles down to an EDIF (Electronic Design Interchange Format) net list, suitable for programming an FPGA.
In conclusion, the path to embedded parallelism described in this paper has proven encouraging on two fronts:
- good parallel efficiency of tricky-to-parallelise applications written to the proposed framework
- positive software engineering experience of functional language use in the concurrent domain.
RaPPID is a 3-year project (EPSRC Contract: GR/N20980) that started in October 2000 at Essex University in association with QinetiQ, Malvern.
Link:
http://www.essex.ac.uk/ese/research/mma_lab/rapid/index.html
Please contact:
David John Johnston, University of Essex, UK
Tel: +44 1206 872912
E-mail: djjohn@essex.ac.uk
|


